GPT4All es un ecosistema para entrenar y desplegar grandes modelos lingüísticos que se ejecutan localmente en ordenadores comunes de consumo. La mayoría de los modelos lingüísticos más populares en la actualidad son patentados. Se ofrecen como un servicio en línea con una suscripción de pago o bajo una licencia restringida. Muchos de estos sistemas no pueden ejecutarse en equipos convencionales debido a su gran tamaño y a los requisitos de hardware.
El proyecto GPT4All pone los modelos lingüísticos a disposición de un mayor número de usuarios. Cualquier persona u organización puede entrenar y desplegar sus propios modelos lingüísticos de gran tamaño utilizando esta herramienta. El equipo de desarrollo de Nomic AI mantiene y desarrolla este sistema, añadiendo regularmente nuevas funciones.
Los modelos GPT4All son archivos de 3 a 8 GB que pueden descargarse y conectarse a una interfaz de software de código abierto. Para un funcionamiento estable, se necesitan de 8 a 16 GB de RAM libre respectivamente. Es decir, la cantidad total de RAM del sistema debería ser aún mayor. La aplicación muestra advertencias si la configuración de su PC no es adecuada para un modelo concreto.
GPT4All ofrece actualmente 11 modelos de idiomas. Esta lista incluye bases locales, así como los servicios en línea ChatGPT 3.5 Turbo y GPT-4. Los chatbots de OpenAI pueden conectarse al software si tienes una suscripción válida y el acceso adecuado a través de una clave API que se encuentra en la configuración de tu cuenta.
Los modelos disponibles en el mercado varían en cuanto al número de instrucciones disponibles, la velocidad de funcionamiento y el estilo de las respuestas. Muchos de los sistemas pueden generar texto y responder a preguntas sobre una amplia gama de temas. Los modelos se entrenan con un amplio conjunto de datos que incluye diálogos verbales, código de programas, poesía, canciones y diversas historias. Aunque el sistema interactúa mejor con el inglés, las consultas en ruso suelen provocar una respuesta con errores.
GPT4All utiliza principalmente la CPU del ordenador para procesar las peticiones. Los usuarios pueden personalizar la longitud máxima de respuesta de la red neuronal estableciendo un gran número de tokens para el límite. Esto ayuda a obtener resultados sin volumen. También es posible establecer manualmente un patrón de consulta para una mejor interacción con los modelos lingüísticos. La correspondencia con el chatbot puede guardarse localmente en el dispositivo.
Es importante tener en cuenta que no todos los modelos GPT4All son adecuados para generar historias o artículos extensos. Además, no en todas las situaciones el chatbot producirá respuestas extensas aunque se establezca un límite grande. Como ya hemos mencionado anteriormente, para modelos voluminosos con un gran número de instrucciones, necesitarás un ordenador con una reserva de RAM - de 24 GB y más. Si tu sistema no cumple este requisito, es mejor que te limites a utilizar modelos compactos.
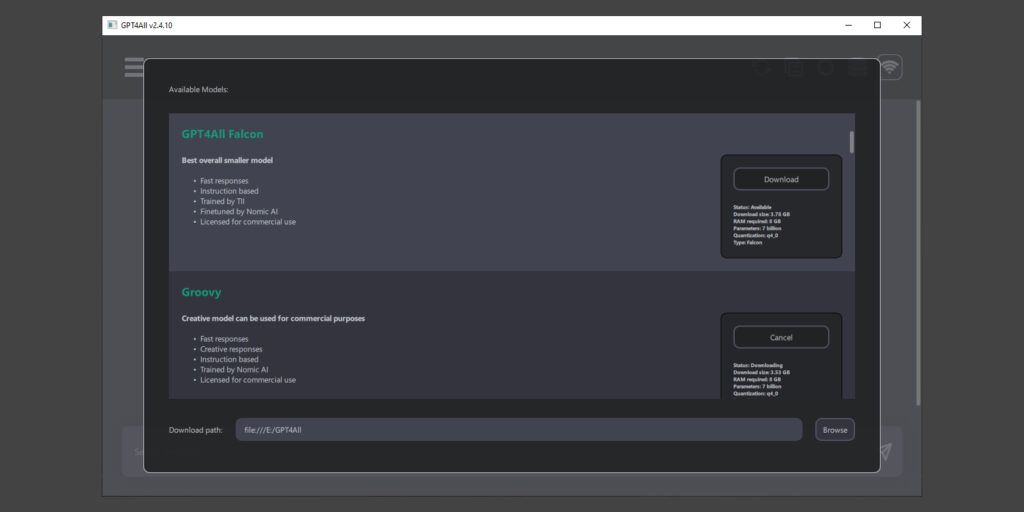
GPT4All está disponible en el sitio web oficial del proyecto. El servicio puede ejecutarse como aplicación de escritorio o mediante una biblioteca Python. La opción más cómoda es instalar un programa con interfaz gráfica para su sistema operativo. Para ello, basta con descargar del sitio el cliente correspondiente con un tamaño de varios cientos de megabytes.
Tras instalar el cliente, se le pedirá que instale uno de los modelos la primera vez que lo ejecute. Puede empezar seleccionando Falcon y LLaMA2. Se trata de conjuntos pequeños que producen respuestas con bastante rapidez. Es cómodo cambiar entre las redes neuronales disponibles: basta con seleccionar la opción deseada en la lista desplegable de la parte superior de la ventana del programa.
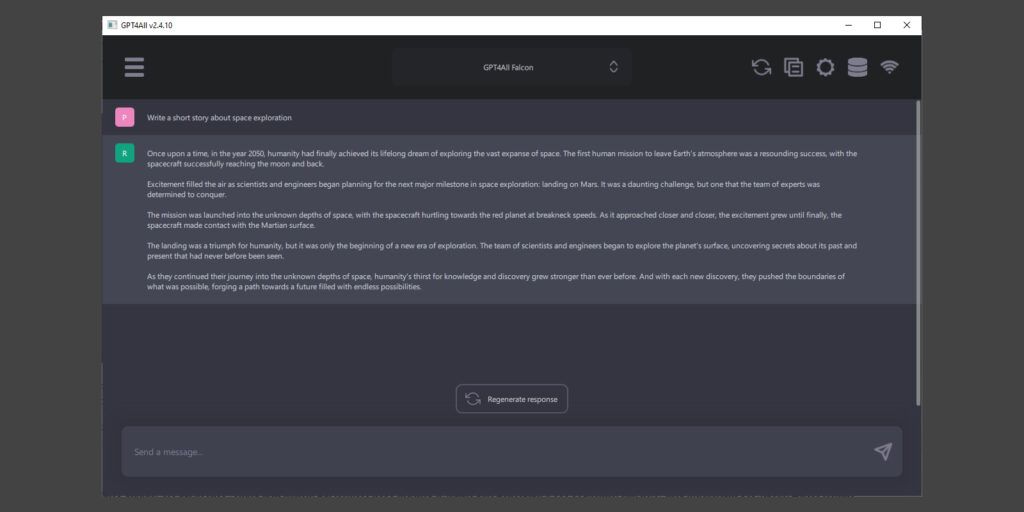
La parte principal de la interfaz de GPT4All es la página de chat. Además del panel para seleccionar los modelos disponibles, también hay un botón para crear un nuevo chat y guardar uno existente. En cualquier momento puedes ir a la pantalla para descargar otros modelos y actualizaciones. En la parte superior derecha están los ajustes básicos y un panel para gestionarlos.
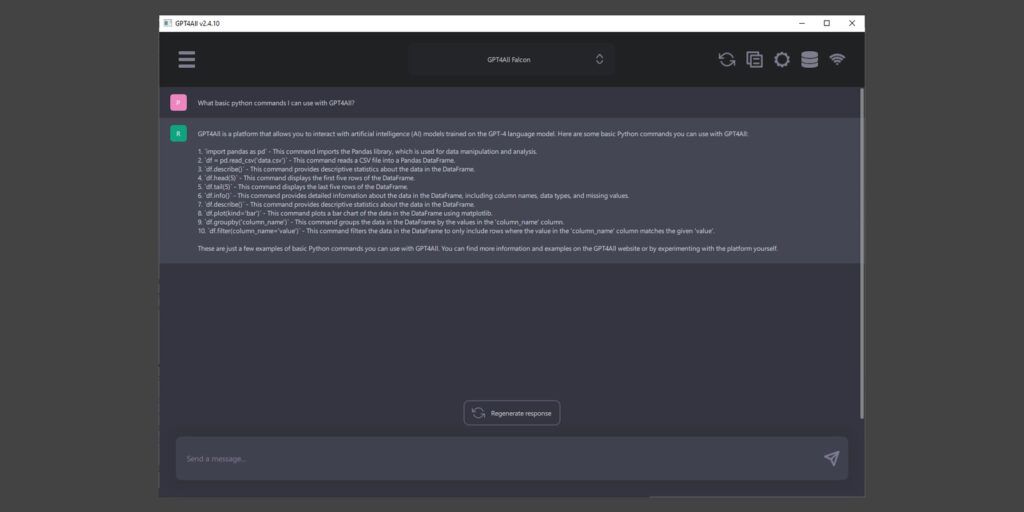
El proceso de trabajo con el chatbot no difiere de otros sistemas en línea similares. Tienes que introducir una consulta detallada en la línea de la parte inferior. Puede añadir aclaraciones o reiniciar la generación de respuestas con el botón correspondiente. Los modelos compactos suelen generar las mismas respuestas varias veces seguidas. Se pueden encontrar resultados interesantes experimentando con diferentes sistemas y seleccionando promts con detalles adicionales.